КАК ЭТО РАБОТАЕТ?
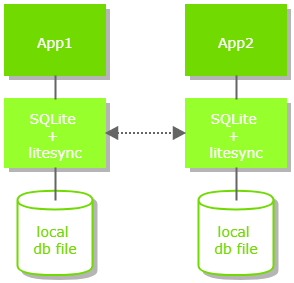
Ваше приложение будет использовать измененную версию библиотеки SQLite, содержащей код LiteSync, для доступа к вашей базе данных.
Изменения в библиотеке SQLite являются внутренними, и имеют такой же интерфейс.
Библиотеки LiteSync будут общаться друг с другом, обмениваясь данными транзакций.
КОПИРОВАНИЕ
Когда приложение открывается в первый раз, оно подключается к другому узлу и загружает свежую копию базы данных.
В централизованной топологии первичный узел отправит копию базы данных вторичным узлам.
После загрузки узел начинает синхронизацию.
СИНХРОНИЗАЦИЯ
Как только узлы имеют одинаковую базу данных, они обмениваются транзакциями, которые были выполнены, когда они находились в автономном режиме.
После этого они входят в режиме онлайн, и как только новая транзакция выполняется в узле, она передается для выполнения в подключенных узлах.
Если узел находится в автономном режиме, то транзакция сохраняется в локальном журнале для последующего обмена.
НУЖНО ЛИ МЕНЯТЬ КОД МОЕГО ПРИЛОЖЕНИЯ?
Есть несколько шагов, но в основном мы должны изменить строку URI в открытой базе данных здесь:
“file:/path/to/app.db”
Примерно вот так:
“file:/path/to/app.db?node=secondary&connect=tcp://server.ip:1234”
Хорошей новостью является то, что LiteSync использует собственный интерфейс SQLite3. Это означает, что нам не нужно использовать другой API.
ПОДКЛЮЧЕНИЕ
Каждый узел имеет 2 варианта:
привязка к адресу
подключение к адресу партнера
Таким образом, вы можете выбрать, какая сторона будет подключаться к другой. Это полезно, когда одна сторона находится позади маршрутизатора или брандмауэра.
ПОДДЕРЖИВАЕМЫЕ ТОПОЛОГИИ
ЦЕНТРАЛИЗОВАННАЯ, ЗВЕЗДНАЯ ТОПОЛОГИЯ
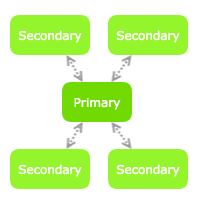
В этой топологии у нас есть узел, к которому будут подключены все остальные узлы, поэтому он должен быть в сети для синхронизации.
Вот несколько примеров конфигураций:
Первичный узел может связываться с адресом, а вторичные узлы соединяются с ним.
Основной узел:
"file:/home/user/app.db?node=primary&bind=tcp://0.0.0.0:1234"
Вторичный узел: (на другом устройстве)
"file:/home/user/app.db?node=secondary&connect=tcp://server:1234"
Основной узел также может подключаться к вторичным узлам.
Основной узел:
"file:/home/user/app.db?node=primary&connect=tcp://address1:port1,tcp://address2:port2"
Вторичные узлы: (каждый на отдельном устройстве)
"file:/home/user/app.db?node=secondary&bind=tcp://0.0.0.0:1234"
Мы можем даже использовать смесь этих двух вариантов.
Основной узел::
"file:/home/user/app.db?node=primary&bind=tcp://0.0.0.0:1234&connect=tcp://address1:port1"
Вторичный Узел 1:
"file:/home/user/app.db?node=secondary&connect=tcp://server:1234"
Вторичный Узел 2:
"file:/home/user/app.db?node=secondary&bind=tcp://0.0.0.0:1234"
Одноранговая топология
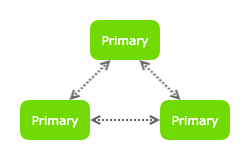
Полностью подключенная одноранговая сеть создается между первичными узлами.
Нам нужно сообщить общее количество узлов в сети вручную на каждом узле (пока)
Также необходимо указать направление соединений (какие узлы к каким будут подключаться).
Вот пример сети с 3 узлами:
Узел 1:
"file:db1.db?node=primary&total_primary_nodes=3&bind=tcp://0.0.0.0:1201"
Узел 2:
"file:db2.db?node=primary&total_primary_nodes=3&bind=tcp://0.0.0.0:1202& connect=tcp://127.0.0.1:1201"
Узел 3:
"file:db3.db?node=primary&total_primary_nodes=3&bind=tcp://0.0.0.0:1203& connect=tcp://127.0.0.1:1201,tcp://127.0.0.1:1202"
Смешанная топология
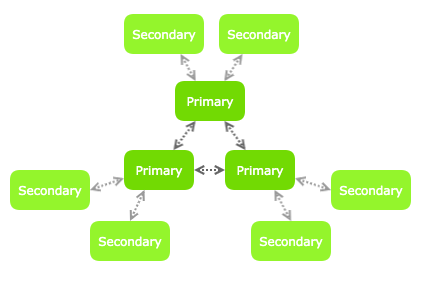
В этой топологии у нас есть более одного первичного узла, подключенного как одноранговые узлы, и много вторичных узлов, подключенных к ним.
Конфигурация основных узлов такая же, как и в одноранговой топологии (см. Выше).
Каждый вторичный узел будет подключен к одному первичному узлу в заданное время. Мы можем сообщить адреса многих первичных узлов, чтобы они выбирали один случайным образом. Если соединение с основным узлом разорвется, он подключится к другому.
Вот пример URI для вторичного узла:
"file:db4.db?node=secondary&connect=tcp://127.0.0.1:1201,tcp://127.0.0.1:1202,tcp://127.0.0.1:1203"
СТАТУС СИНХРОНИЗАЦИИ
Мы можем проверить состояние синхронизации с помощью этой команды:
PRAGMA sync_status
Возвращает строку JSON.
Уведомление о синхронизации
Ваше приложение может быть уведомлено, когда локальная база данных обновляется из-за синхронизации с удаленными узлами. Уведомление осуществляется с помощью пользовательской функции.
Выберите язык -->
static void on_db_update(sqlite3_context *context, int argc, sqlite3_value **argv){ puts("обновление получено"); } sqlite3_create_function(db, "update_notification", 1, SQLITE_UTF8, NULL, &on_db_update, NULL, NULL);
def on_db_update(arg): print("обновление получено") con.create_function("update_notification", 1, on_db_update)
// using better-sqlite3: db.on('sync', function() { console.log('обновление получено'); });
Function.create(conn, "update_notification", new Function() { protected void xFunc() { System.out.println("обновление получено"); } });
// using SQLite.NET: db.OnSync(() => { // the db received an update. update the screen with new data UpdateScreen(db); }); // using Microsoft.Data.SQLite: db.CreateFunction("sync_notification", () => { // notification received on the worker thread // do not access the db connection here // transfer the notification to the main thread Console.WriteLine("обновление получено"); });
' Using SQLite.NET: db.OnSync(Sub() ' the db received an update. update the screen with new data UpdateScreen(db) End Sub) ' Using Microsoft.Data.SQLite: db.CreateFunction("sync_notification", Sub() ' notification received on the worker thread ' do not access the db connection here ' transfer the notification to the main thread Console.WriteLine("обновление получено") End Sub)
function on_db_update($string) { echo 'обновление получено'; } // with sqlite3: $db->createFunction('update_notification', 'on_db_update'); // with pdo_sqlite: $db->sqliteCreateFunction('update_notification', 'on_db_update', 1);
$dbh->sqlite_create_function( 'update_notification', 1, sub { print 'обновление получено' } );
db.create_function "update_notification", 1 do |func, db| puts 'обновление получено' func.result = null end
db.create(function: "update_notification", argc: 1) { args in println("обновление получено") return nil }
db:create_function('update_notification',1,function(ctx,db) print('обновление получено') ctx:result_null() end))
func on_db_update() int64 { print('обновление получено') return null } sql.Register("sqlite3_custom", &sqlite.SQLiteDriver{ ConnectHook: func(conn *sqlite.SQLiteConn) error { if err := conn.RegisterFunc("update_notification", on_db_update, true); err != nil { return err } return nil }, }) db, err := sql.Open("sqlite3_custom", "file:data.db?node=...")
Важно: функция уведомления вызывается рабочим потоком. Приложение НЕ должно использовать соединение с базой данных внутри функции уведомления, и оно должно возвращаться как можно быстрее! Приложение может передать уведомление в основной поток перед возвратом.
ПРОВЕРКА, ЕСЛИ БАЗА ДАННЫХ ГОТОВА
Если приложение открывается на устройстве в первый раз, оно может загрузить новую копию базы данных с другого узла. Пока это не сделано, мы не можем получить доступ к базе данных
Мы можем получить статус синхронизации и проверить переменную db_is_ready
Проверьте основные примеры приложений ниже.
Как использовать это в моем приложении?
Есть 3 шага:
1 Замените библиотеку SQLite библиотекой, содержащей LiteSync.
2 Измените строку подключения URI
3 Проверьте состояние готовности БД
При компиляции приложений C и C ++ вы должны связать свое приложение с библиотекой LiteSync.
Для других языков вы должны иметь соответствующую установленную оболочку.
ПЕРВИЧНЫЙ ПРИМЕР УЗЛА
Первичный узел может быть обычным приложением, точно таким же, что и вторичные узлы, но с другим URI.
Или мы можем использовать приложение, предназначенное для основного узла.
Базовое автономное приложение, используемое исключительно для сохранения централизованного узла БД, будет выглядеть так:
Выберите язык -->
#include <sqlite3.h> char *uri = "file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234"; int main() { sqlite3 *db; sqlite3_open(uri, &db); /* open the database */ while(1) sleep(1); /* keep the app open */ }
import litesync as sqlite3 conn = sqlite3.connect('file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234') # keep the app open import time while True: time.sleep(60) # in seconds
const uri = 'file:app.db?node=primary&bind=tcp://0.0.0.0:1234'; const options = { verbose: console.log }; const db = require('better-sqlite3-litesync')(uri, options); // keep the app open setInterval(function(){}, 5000);
import java.sql.Connection; import java.sql.DriverManager; public class Sample { public static void main(String[] args) { String uri = "file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234"; Connection connection = DriverManager.getConnection("jdbc:sqlite:" + uri); // keep the app open while (true) { Thread.sleep(5000); } } }
using SQLite; public class Program { public static void Main() { // open the database var uri = "file:app.db?node=primary&bind=tcp://0.0.0.0:1234"; var db = new SQLiteConnection(uri); // keep the app open while(true) { System.Threading.Thread.Sleep(5000); } } }
Imports SQLite Public Class Program Public Shared Sub Main() ' open the database Dim db As New SQLiteConnection("file:app.db?node=primary&bind=tcp://0.0.0.0:1234") ' keep the app open Do System.Threading.Thread.Sleep(5000) Loop End Sub End Class
Option Explicit Declare Sub Sleep Lib "kernel32.dll" (ByVal dwMilliseconds As Long) Public Sub Main() Dim URI As String Dim Conn As New ADODB.Connection ' Open the connection URI = "file:C:\app\mydb.db?node=primary&bind=tcp://0.0.0.0:1234" Conn.Open "DRIVER=SQLite3 ODBC Driver;Database=" & URI ' Keep the app open Do: Sleep(5000): Loop End Sub
<?php // with sqlite3: $db = new SQLite3("file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234"); // with pdo_sqlite: $pdo = new PDO("sqlite:file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234"); // keep the app open - it should not be used with apache while(1) sleep(5); ?>
use DBI; my $dbh = DBI->connect("dbi:SQLite:uri=file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234"); // keep the app open - it should not be used with apache sleep;
require 'sqlite3' db = SQLite3::Database.new "file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234" # keep the app open loop do sleep(1) end
local sqlite3 = require("lsqlite3") local db = sqlite3.open('file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234') -- keep the app open local lsocket = require("lsocket") while true do lsocket.select(5000) end
package main import ( "database/sql" _ "github.com/litesync/go-sqlite3" "time" ) func main() { db, err := sql.Open("sqlite3", "file:/path/to/app.db?node=primary&bind=tcp://0.0.0.0:1234") // keep the app open for { time.Sleep(1000 * time.Millisecond) } }
ПРИМЕР ОСНОВНОГО ПРИЛОЖЕНИЯ
Базовое приложение, которое пишет в локальную базу данных, будет выглядеть так:
Выберите язык -->
#include <sqlite3.h> char *uri = "file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234"; int main() { sqlite3 *db; /* open the database */ sqlite3_open(&db, uri); /* check if the db is ready */ while(1){ char *json_str = sqlite3_query_value_str(db, "PRAGMA sync_status"); BOOL db_is_ready = sqlite3_json_get_bool(json_str, "db_is_ready"); sqlite3_free(json_str); if (db_is_ready) break; sleep_ms(250); } /* access the database */ start_access(db); }
import litesync as sqlite3 import json import time conn = sqlite3.connect('file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234') # check if the db is ready while not conn.is_ready(): time.sleep(0.250) start_access(conn)
const uri = 'file:test.db?node=secondary&connect=tcp://127.0.0.1:1234'; const options = { verbose: console.log }; const db = require('better-sqlite3-litesync')(uri, options); db.on('ready', function() { // the database is ready to be accessed db.exec('CREATE TABLE IF NOT EXISTS users (name, email)'); ... });
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; import org.json.*; public class Sample { public static void main(String[] args) { String uri = "file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234"; Connection connection = DriverManager.getConnection("jdbc:sqlite:" + uri); Statement statement = connection.createStatement(); // check if the db is ready while (true) { ResultSet rs = statement.executeQuery("PRAGMA sync_status"); rs.next(); JSONObject obj = new JSONObject(rs.getString(1)); if (obj.getBoolean("db_is_ready")) break; Thread.sleep(250); } // now we can access the db start_access(connection); } }
using SQLite; public class Program { public static void Main() { // open the database var uri = "file:app.db?node=secondary&connect=tcp://server:port"; var db = new SQLiteConnection(uri); // wait until the db is ready while (!db.IsReady()) { System.Threading.Thread.Sleep(250); } // now we can use the database db.CreateTable<TodoItem>(CreateFlags.AutoIncPK); ... } }
Imports SQLite Public Class Program Public Shared Sub Main() ' open the database Dim db As New SQLiteConnection("file:app.db?node=secondary&connect=tcp://server:port") ' wait until the db is ready While Not db.IsReady() System.Threading.Thread.Sleep(250) End While ' now we can use the database db.CreateTable(Of TodoItem)(CreateFlags.AutoIncPK) ' ... End Sub End Class
Option Explicit Declare Sub Sleep Lib "kernel32.dll" (ByVal dwMilliseconds As Long) Public Sub Main() Dim Conn As New ADODB.Connection Dim Rst As ADODB.Recordset Dim URI As String URI = "file:C:\app\mydb.db?node=secondary&connect=tcp://myserver.ddns.net:1234" Conn.Open "DRIVER=SQLite3 ODBC Driver;Database=" & URI ' Check if the database is ready Do Set Rst = New ADODB.Recordset Rst.Open "PRAGMA sync_status", Conn, , , adCmdText If InStr(Rst!sync_status, """db_is_ready"": true") > 0 Then Exit Do Sleep 200 Loop ' Now we can access the db StartDbAccess(Conn) End Sub
<?php // with sqlite3: $db = new SQLite3("file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234"); // with pdo_sqlite: $pdo = new PDO("sqlite:file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234"); // check if the db is ready while(1) { $results = $db->query('PRAGMA sync_status'); $row = $results->fetchArray(); $status = json_decode($row[0], true); if ($status['db_is_ready'] == true) break; sleep(0.25); } // now we can access the db start_access($db); ?>
use DBI; use JSON qw( decode_json ); my $dbh = DBI->connect("dbi:SQLite:uri=file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234"); // check if the db is ready - it should not be used with apache while (1) { my ($result) = $dbh->selectrow_array("PRAGMA sync_status"); my $status = decode_json($result); if ($status->{'db_is_ready'}) last; sleep; } // now we can access the db ...
require 'sqlite3' require 'json' db = SQLite3::Database.new "file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234" # check if the db is ready loop do result = db.get_first_value "PRAGMA sync_status" status = JSON.parse(result) break if status["db_is_ready"] == true sleep 0.25 end # now we can access the db start_access(db)
local sqlite3 = require "lsqlite3" local json = require "json" local db = sqlite3.open('file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234') -- check if the db is ready local lsocket = require("lsocket") while true do local result = db:rows("PRAGMA sync_status") local status = json:decode(result[0]) if status["db_is_ready"] == true then break end lsocket.select(250) end -- now we can access the db start_access(db)
package main import ( "database/sql" _ "github.com/litesync/go-sqlite3" "time" ) func main() { db, err := sql.Open("sqlite3", "file:/path/to/app.db?node=secondary&connect=tcp://myserver.ddns.net:1234") // wait until the db is ready for !db.IsReady() { time.Sleep(1000 * time.Millisecond) } // now we can access the db start_access(db) }
ТЕКУЩИЕ ОГРАНИЧЕНИЯ
1 Избегайте использования функций, которые возвращают разные значения при каждом вызове, например random() и date('now')
2 Ключевое слово AUTOINCREMENT не поддерживается
3 Мы должны использовать только одно соединение с каждым файлом базы данных. Не позволяйте нескольким приложениям обращаться к одному и тому же файлу базы данных. Каждый экземпляр должен использовать свой собственный файл базы данных, а затем они будут реплицироваться и синхронизироваться с помощью LiteSync.